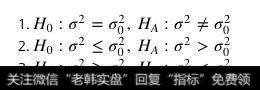基于小样本预测总体,我们称之为统计推断,它常常被划分为两个部分,估计与假设检验。估计部分会得到你所关注的一些特征值,如均值与方差(以及相关的置信区间)。
注:置信区间部分可参见本系列上篇文章《Quantopian量化交易(12)—置信区间》。
假设检验部分则关注于另一面,为假设值的统计检验提供详细的操作框架。
在进行统计检验的时候,要时刻牢记的一点是,只有当所有必要条件均满足时,你才能得到证券的结果,当你基于假设检验接受某个假设时,也并不能说明该假设就一定正确,只能得到该假设有多大的概率是谬误的。
原假设与备择假设
我们首先来介绍原假设,通常被写作H0,原假设为默认情况,通常表示现实世界中普遍被认可的假设(希望予以反对),备择假设(Ha)则表示你希望通过证据予以支持的假设。
例:
1、备择假设Ha是你有超过10双的鞋子,原假设H0为你没有10双以上的鞋子
2、备择假设Ha为吃披萨与肥胖有关,原假设H0为两者没有关系
3、备择假设Ha为微软的平均回报>0,原假设H0为<=0
有些情况下,检验还会遇到各种困难,如例1中就的情况就很容易进行检验,但即便如此,因为可能存在的计量误差,也可能会导致出现存在偏差的结果;
另外的一些情况下,例如“地球上昆虫的种类比宇宙中的星星要多”,这种假设因为需要收集海量的数据,则更加难以进行。
假设必须是可以验证的,例如“动量交易是一个赚钱的好途径”,这个假设就是不可验证的,哪种类型的动量交易?好是怎么定义的?这些不够明确的描述都会导致假设的不可检验。
如何进行假设检验
步骤:
声明原假设与备择假设
确定合适的检验统计量与分布。确保基于数据的所有假设都满足(如平稳性、正态性)
指定置信水平α
根据α和分布计算临界值
收集数据,计算检验统计量
比较检验统计量与临界值,确定是能否拒绝原假设
首先需要声明我们希望检验的假设,包含一个原假设与一个备择假设。
例如我们想要检验微软股票的持有收益是否为0,设定统计量为θ,其推荐值为θo(本例中为0)。那么我们的假设就可以写作:

假设
当然在不同情况下还可能有其他的几种情况:

备择假设的不同情况
其中第一种情况叫做双边假设检验,下面两种则被称为单边假设检验,第二种情况在θ大于θo的时候拒绝原假设,第三种情况则相反。而双边假设在θ大于或者小于θo的时候均拒绝原假设。
在构建假设时,必须保证原假设与备择假设是互补的,两者必须覆盖θ的所有取值。
在现实中最为常见的还是双边检验,因为不等于代表了一种中立的态度。单边检验常常包含了实验者的一种设想,常常用来验证一些“期望”得到的结果。
在开始下一步之前,我们先获取一下微软2015年全年的股票价格数据,并以此得到其收益变化。

示例代码
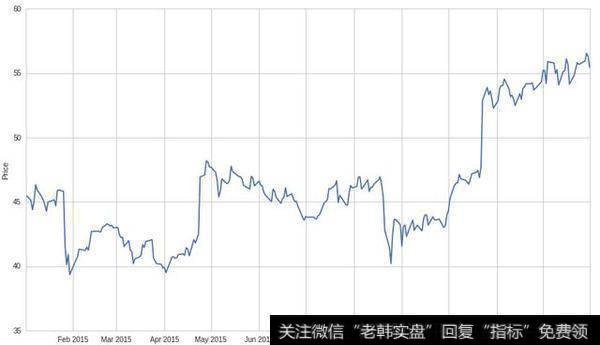
价格变化图

收益波动图
为什么需要假设检验?
可能大家都心存疑惑,为什么不能直接算出微软的平均收益来判断它是否不为0呢?这是因为我们只能获取到特定时间的一些样本数据,而这些样本是否能够正确反映总体的真实情况,是无法得知的。
检验统计量 & 常用分布
第二步,我们就需要确定合适的检验统计量及其可能服从的分布。检验统计量的一般形式如下:
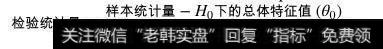
检验统计量一般形式
基于样本数据计算检验统计量,并与其概率分布进行比较,最终得出是否能够拒绝原假设的结论。在本例中,我们可以得到检验统计量为:

检验统计量
四种最常用的分布对应了四种最为常见的假设检验:
t-分布→t-检验
标准正态分布→z-检验
卡方分布→χ方检验
F分布→F检验
下文会根据不同常见详述各检验运用的场景,在微软收益的例子中,我们选择z-检验。
置信水平
第三步,需要确定检验的置信水平α,基于一个确定的置信水平后,才能使用检验统计量进行判断是否拒绝假设。
如何理解置信水平?这里引入一个概率矩阵
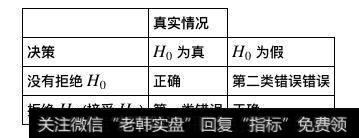
概率矩阵
注:置信水平α就等于第一类错误发生的概率(拒真),相对应第二类错误(取伪)发生的概率通常用β进行表示。在样本情况不变的情况下,如果我们试图降低第一类错误发生的概率,则第二类错误发生的概率则会上升。只有通过增大样本大小,才能同时降低发生两类错误的概率。在置信水平越高的情况下拒绝原假设,代表我们有更大的把握认为原假设是不准确的。
临界值
第四步,根据显著水平α与检验使用的分布,计算临界值(也被称为拒绝点)。临界值用于确定是否能够拒绝原假设,如果可以,则该结果称为统计上显著,否则称为统计上不显著。
举个栗子,如果我们取置信水平α为0.05,那么对于一个单边的z-检验,则有以下两种情况:
单边z-检验
双边检验略有不同,因为它有两个临界值,一正一负。还是以0.05的置信水平为例,因为是双边检验,所以需要将0.05切分为两个0.025,于是我们可以得到如下两个临界值

双边的临界值
依旧是z-检验,可以算出这两个临界值为1.96与-1.96,如果z<-1.96或者z>1.96,则可以拒绝原假设。
p值
在进行假设检查时,也可以根据p值去确定结果。p值是你可以拒绝原假设的最小置信水平。注意p值不能理解为“原假设为假的概率”。p值只有与置信水平比较时才有意义,如果p值小于置信水平α,就可以拒绝原假设,反之则不行。但p值的大小本身没有意义,不能认为p值越小,则统计学上更显著。
p值的计算公式,可以通过累积密度函数(CDF)计算得到

p值计算公式
均值的假设检验
z-分布/标准正态分布,因其本身许多有用的性质,使得其成为金融中最为重要的一个概率分布,许多的基本方法都是基于正态分布的假设。但是,对于许多情况来说z-分布并不适用,我们很少能够得到数据的真实参数(均值,方差),所以经常要依赖于近似处理,这些情况下,可以使用t-分布,可以看做z-分布的一个近似。
注:1、 t-分布在小样本下可以使用,并且使用的是样本均值与方差。相对于z-分布来说,t分布是“尖峰肥尾”的
2、t-分布与z-分布都依赖于正态分布的假设。
除了上小节例子检验单个均值的情况,假设检验还也可以使用比较多个均值。下面就以t-分布为例,来比较一下标普500与苹果的平均收益。
两者收益确实具有相同的均值,接下来就需要使用假设检验来验证这个假设
当比较两个均值时,假设可分为以下几种类型:

均值比较
方差的假设检验
在金融中,方差、标准差对应于风险,所以对于方差的检验非常的重要且常见。但此时z-分布与t-分布就力所不及了,这里就需要引入新的分布类型。
根据定义,方差是大于或等于0的,但是目前已学得z-分布与t-分布,都允许负值的存在,这里我们引入卡方分布(用于单方差检验)与F-分布(多方差检验),这两类分布的值均在0之上。
同样也可有以下三种形式: